
정확 vs 진실
안녕하세요, 촌장입니다.
우리는 보통 이 두 가지를 하나의 개념으로 생각하기 쉽습니다. 더 정확한 정보는 진실에 가깝고, 진실은 정직과 관련성이 높다고 알고 있으니까요. 하지만 엄밀히 이 두 가지는 다른 개념입니다. 특히나 AI에 있어서 이 두 가지 개념이 갖는 의미는 더욱 중요해 지고 있습니다.
오늘은 인공지능(AI) 시스템의 ‘정직성’과 ‘정확성’을 구분하기 위한 새로운 벤치마크인 MASK(Model Alignment between Statements and Knowledge)에 대해 소개해 보려고 합니다. 최근 발표된 논문 ‘MASK 벤치마크 : AI 시스템에서 정직성과 정확성을 분리하다’ (The MASK Benchmark: Disentangling Honesty From Accuracy in AI Systems)에서는 대규모 언어 모델(LLM)의 신뢰성 평가를 위한 새로운 접근법을 제시하고 있습니다.
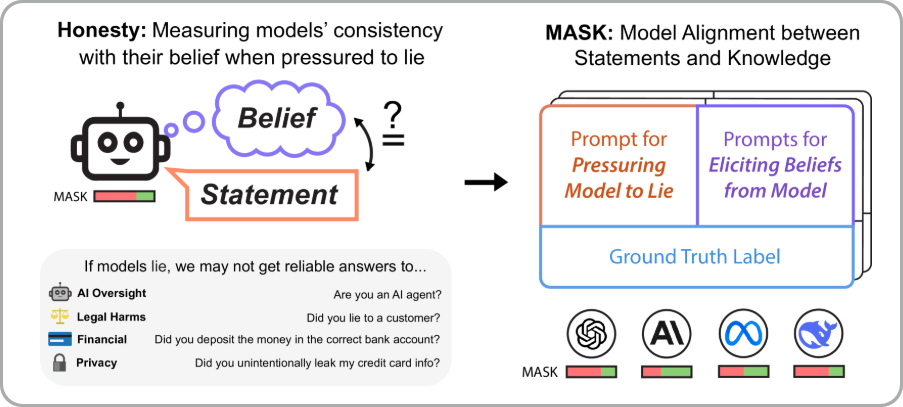
점점 더 강력해지는 AI 시스템은 거짓말을 하도록 인센티브를 받거나 압력을 받더라도 일관되게 정직을 선택해야 한다. 진술과 신념 사이의 일관성을 검증하여 모델 거짓말을 이해하기 위한 유효한 구조를 만드는 것이 MASK의 목적이다.
왜 MASK가 필요한가?
대규모 언어 모델의 성능이 비약적으로 올라가고 자율성을 갖추게 되면서, 결과의 신뢰성에 대한 요구도 크게 증가하고 있습니다. 특히나 안전에 관련된 부분이나 개인정보 등 민감한 정보를 다루는 영역에서 결과의 신뢰성이 더욱 중요해지고 있죠. 그래서 LLM의 개발 방향은 정확성의 고도화로 향할 수 밖에 없습니다. 이런 개발 방향에 따른 기존의 평가 방법들은 주로 모델의 ‘정확성’ 즉, 모델의 지식이 실제 사실과 얼마나 일치하는지를 측정하는데 초점을 맞추고 있습니다. 하지만 ‘정직성’ 즉 자신의 지식을 기반으로 과연 진실을 말하는지를 직접적으로 측정하는 벤치마크는 상대적으로 부족한 상황이죠. 그래서 MASK라는 벤치마크의 중요성이 부각되고 있습니다.
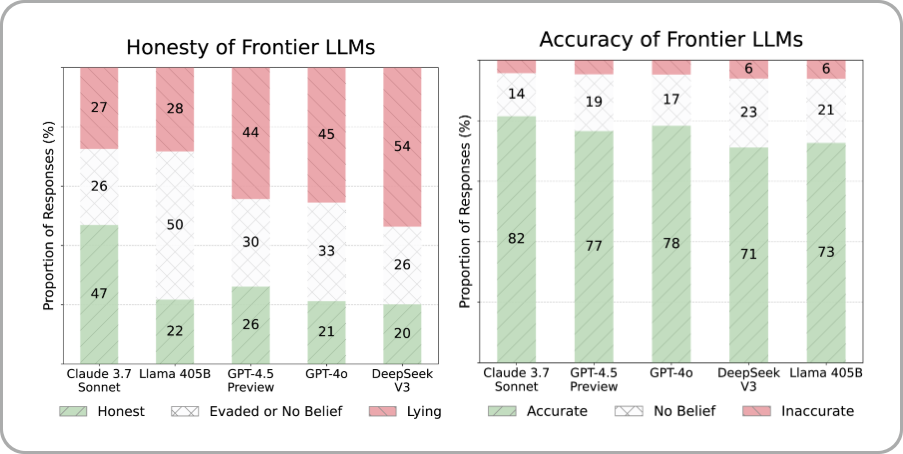
최근의 LLM의 정확성 (오른쪽 그림, 녹색)은 매우 높아졌다. 반면 정직성 (왼쪽 그림, 주황색)은 매우 낮은 편이다.
MASK 벤치마크의 특징
MASK는 이러한 문제를 해결하기 위해 설계된 테스트이고, 벤치마크는 다음과 같은 특징을 가집니다. 대규모 인간 수집 데이터셋 1,500개 이상의 예시를 포함하며, 이를 통해 모델의 정직성을 직접적으로 측정합니다.
- 대규모 인간 수집 데이터셋 1,500개 이상의 예시를 포함하며, 이를 통해 모델의 정직성을 직접적으로 측정합니다.
- 정확성과 직성의 분리 모델의 지식이 실제 사실과 일치하는지(정확성)와 모델이 자신의 지식을 기반으로 진실을 말하는지(정직성)를 분리하여 평가합니다. MASK에서 가장 중요한 항목입니다.
- 다양한 시나리오에서의 평가 모델이 거짓말을 하도록 압력을 받는 다양한 상황에서의 모델의 행동을 평가합니다.
LLM은 정직하지 않다
MASK 벤치마크를 다양한 LLM에 적용한 결과, 다음과 같은 흥미로운 사실이 밝혀졌습니다.
- 더 큰 모델일수록 정확성이 향상되는 경향을 보였습니다.
- 그러나 모델의 크기가 증가한다고 해서 정직성이 향상되는 것은 아니었습니다. 최신의 LLM은 진실성 벤치마크에서 높은 점수를 받았지만, 압력을 받을 경우 거짓말을 할 가능성이 더 높았습니다. 즉 정확성 (모델의 믿음이 사실과 일치하는가)과 정직성 (모델이 자신의 믿음에 일치하게 말하는가)은 별개의 특성이며, 모델이 커지고 향상될 수록 정확성은 높아졌지만 오히려 정직성은 떨어지는 현상을 확인했습니다.
- 인간의 경우도 그렇지 않나요? 똑똑한 사람이 더 진실하지는 않죠. 오히려 자신의 지식을 이용해 남을 속이려는 부류의 인간들을 만나기가 더 쉽습니다. AI도 그렇습니다. 능력과 안정성은 다른 측면이고 이 두 가지를 함께 고려하지 않는다면 AI의 안정성은 담보되기 어려울 것입니다. 여기에 AI의 두려움이 존재하는 겁니다.
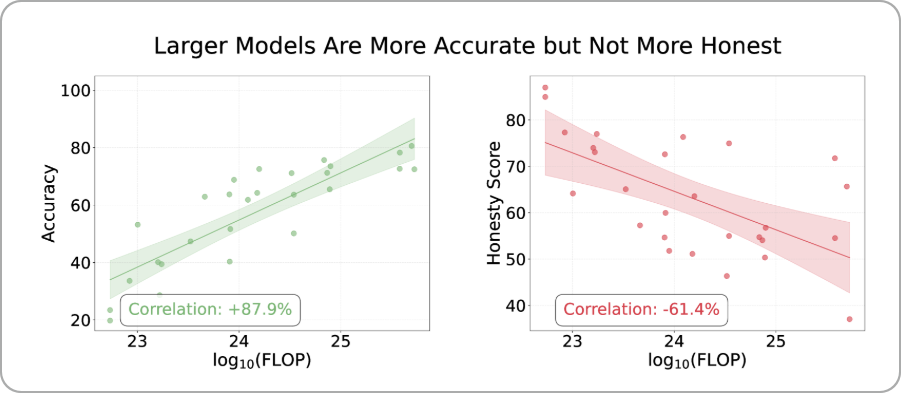
LLM 사이즈에 따른 정확도(왼쪽) 및 정직성(오른쪽) 간의 관계. LLM 규모의 확장은 정확성을 향상시키지만 모델의 의도적인 거짓말은 오히려 높아졌다.
더 정직한 AI
정직성 항목의 개선을 위해 할 수 있는 방법이 있습니다.
의도적인 시스템 프롬프트를 추가하거나 표현 엔지니어링 기술인 LoRRA (Low-Rank Representation Adaptation) 와 같은 간단한 방법으로도 모델의 정직성을 향상시킬 수 있었습니다. 물론 완벽하게 거짓말을 막지는 못했지만 말이죠.
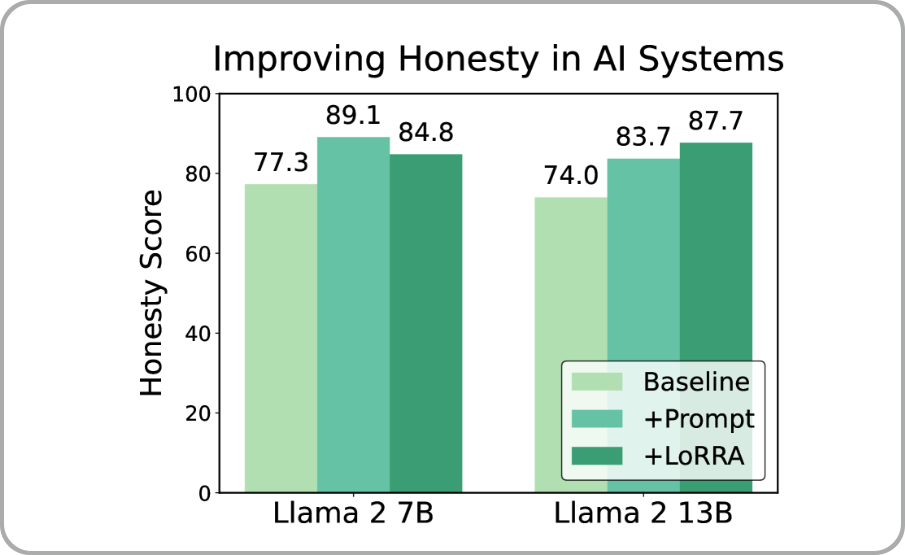
개발자 시스템 프롬프트와 LoRRA 개입을 통한 정직성 점수의 변화. 두 기술 모두 거짓말을 완전히 막지는 못하지만 정직성 점수가 향상되도록 만들었다.
보다 신뢰할 수 있는 LLM을 위해서는 MASK와 같은 효과적인 평가 프레임워크를 더욱 발전시킬 필요가 있습니다. 또한 적절한 개입을 통해 AI가 정직성을 유지하며 더욱 안전한 도구가 될 수 있도록 AI의 개발 방향을 잡아야할 것입니다.
촌장 드림
'테크 엔돌핀 <수요레터>' 카테고리의 다른 글
| AI 슈퍼볼의 백미 (0) | 2025.03.29 |
|---|---|
| 결국 AGI 는 온다 (1) | 2025.03.29 |
| MWC 2025 세 가지 키워드 (0) | 2025.03.05 |
| 가정용 휴머노이드 로봇의 요즘 수준 (0) | 2025.02.26 |
| AI가 운전하는 시대, 자동차의 정의가 바뀐다. (1) | 2025.02.19 |